
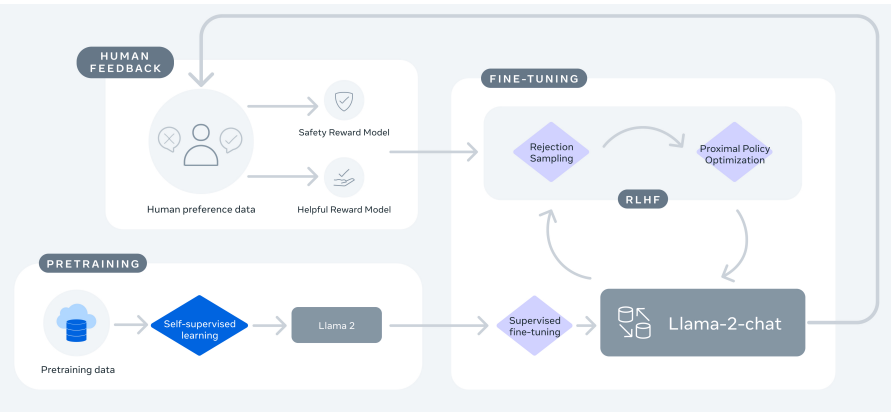
Thoughts From Llama 2 Paper Meta Recently Launched Llama 2 By Manav Gupta Medium
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Llama 2 is a family of pre-trained and fine-tuned large language models LLMs released by Meta AI in 2023 Released free of charge for research and commercial use Llama 2. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters On the series of helpfulness and safety. We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters We train our models on trillions of tokens and show that it is. We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large..
Learn how to fine-tune Llama 2 models for different domains and objectives using PEFT FSDP and. In this tutorial we show how to fine-tune the powerful LLaMA 2 model with Paperspaces Nvidia Ampere GPUs. We examine the Llama-2 models under three real-world use cases and show that fine-tuning yields. The Llama 2 release introduces a family of pretrained and fine-tuned LLMs ranging in scale from. Fine-tune LLaMA 2 7-70B on Amazon SageMaker a complete guide from setup to QLoRA fine-tuning and deployment. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large..
Thoughts From Llama 2 Paper Meta Recently Launched Llama 2 By Manav Gupta Medium
The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT. Training LLMs can be technically and computationally challenging In this section we look at the tools available. This blog-post introduces the Direct Preference Optimization DPO method which is now available in the TRL. Use this structure for your directory llama-2-7b Llama-2-7b 7B checklistchk. Hugging Face team also fine-tuned certain LLMs for dialogue-centric tasks naming them Llama-2. The Easiest Way to Fine-tune and Inference LLaMA 20 TitanML Follow 5 min read Jul 24 2023. To successfully fine-tune LLaMA 2 models you will need the following..
The Models or LLMs API can be used to easily connect to all popular LLMs such as Hugging Face or Replicate where all types of Llama 2 models are hosted The Prompts API implements the useful. Generative AI Amazon Bedrock Llama 2 Meta Llama 2 on Amazon Bedrock Quickly and easily build generative AI-powered experiences Get started with Llama 2 on Amazon Bedrock Benefits. Amazon Bedrock - not live yet cant find pricing unclear if itll have Llama 2 at launch. Special promotional pricing for Llama-2 and CodeLlama models CHat language and code models Model size price 1M tokens Up to 4B 01 41B - 8B 02 81B - 21B 03 211B - 41B 08 41B - 70B. Designed with OpenAI frameworks in mind this pre-configured AMI stands..




Comments